Type 2 Diabetes Risk Prediction Model
This project develops machine learning models to predict diabetes status and identify key risk factors using survey data from the CDC’s Behavioral Risk Factor Surveillance System (BRFSS) 2022 dataset, containing 445,132 participants across 328 variables.

Key Approach:
- Selected 15 relevant health and demographic features through literature review and statistical analysis
- Cleaned dataset to 291,267 records (65% of original data)
- Addressed significant class imbalance (83% non-diabetic, 17% diabetic/pre-diabetic)
Models Tested:
- Naïve Bayes: Multiple variants (Gaussian, Multinomial, Bernoulli, Complement)
- Decision Tree: With hyperparameter tuning and class weighting
Key Findings:
Through exploratory data analysis and feature selection (PCA and filter methods), the most important diabetes risk factors identified were:
- Age and general health status
- Arthritis and heart disease history
- Education and income level
- Exercise habits
Final Model: Class-weighted Decision Tree
- Recall: 0.72 (successfully identifies 72% of diabetes cases)
- Precision: 0.27 (27% of positive predictions are correct)
- Prioritized recall over precision to minimize missed diabetes diagnoses
Conclusion:
The model effectively identifies most diabetes patients despite generating false positives, which aligns with the medical priority of early detection over unnecessary testing costs.
Reference
To simplify the work, features to use before EDA and feature selection was selected based on the paper used dataset before 2019:
Xie, Z., Nikolayeva, O., Luo, J., & Li, D. (2019). Building Risk Prediction Models for Type 2 Diabetes Using Machine Learning Techniques. Preventing chronic disease, 16, E130.
Comparison with previous research (Xie et al. (2019))
Results of Xie et al. (2019): 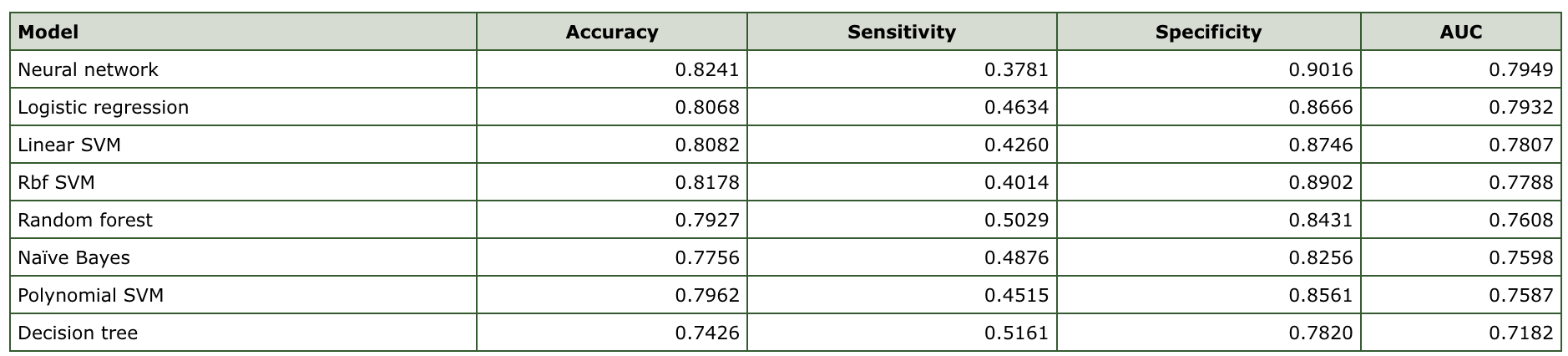
Results of this project: 
The Recall of DT has been increase by about 20% (51.61% ➡ 72%)
Key Takeaway
The main competitive advantage of this project is its focus on practical medical relevance over pure statistical performance, making it more suitable for real-world healthcare applications where missing a diabetes diagnosis has more serious consequences than false alarms.
| Aspect | This Project | Xie et al. (2019) | Improvement |
|---|---|---|---|
| Dataset Size | 445,132 records (291,267 after cleaning) | Smaller dataset (exact size not specified) | ✅ Significantly larger sample size for better generalizability |
| Data Recency | BRFSS 2022 | Pre-2019 data | ✅ More current health trends and patterns |
| Class Imbalance Handling | Multiple strategies: Complement Naive Bayes + Class-weighted Decision Trees | Standard approaches | ✅ Innovative solutions specifically designed for imbalanced datasets |
| Model Selection Criteria | Medical context-driven (Type I vs Type II errors) | Primarily statistical metrics | ✅ Clinically relevant decision-making framework |
| Performance Priority | Recall-focused (0.72 recall, 0.27 precision) | Likely accuracy/precision focused | ✅ Prioritizes catching diabetes cases over false positives |
| Feature Selection | Combined PCA + Filter methods with extensive EDA | Traditional feature selection | ✅ Multi-method approach with comprehensive visualization |
| Class Imbalance Recognition | Explicit handling of 83%/17% distribution | May not address severe imbalance | ✅ Acknowledges that high accuracy can be misleading |
| Medical Justification | Clear rationale for diabetes detection priority | Statistical focus | ✅ Considers real-world clinical consequences |
| Practical Application | Honest assessment of trade-offs for practitioners | Academic performance metrics | ✅ Actionable insights for healthcare implementation |
Future Work
- Clean all features in the dataset
- Polish the survey questions based the chosen features and outlier pattern
- Build the platform for people to answer the updated questions and calculate the risk of type-2 diabetes
- AI chatbox and report