Fraud Detection by Machine Learning
A comprehensive machine learning pipeline for detecting fraudulent transactions with 99% accuracy. This project tackles extreme class imbalance using advanced techniques including SMOTE, ensemble methods, and automated hyperparameter optimization to protect financial systems in real-time.
Highlights
- Complete ML Pipeline: End-to-end fraud detection system from raw data to production-ready model
- Advanced Imbalance Handling: Tackles 0.2% fraud rate using:
- SMOTE (Synthetic Minority Over-sampling Technique)
- Automated ensemble balancing methods
- Cost-sensitive learning approaches
- Multiple Model Comparison: Comprehensive evaluation of:
- Logistic Regression (baseline)
- Random Forest Classifier
- XGBoost with optimized hyperparameters
- Neural Networks with custom architecture
- Feature Engineering Excellence:
- Statistical feature creation and transformation
- PCA for dimensionality reduction
- Mutual information-based feature selection
- Domain-specific fraud indicators
- Real-time Performance: Sub-50ms prediction latency suitable for production deployment
- Huge Dataset Processing: To deal with One Million records, optimized data types and used efficient tech, such as SQL-based Approach with DuckDB, parallel execution, etc.
Key Achievements
- 53.46% Fraud Detection Rate: Catches more than half fraudulent transactions
- <0.5% False Positive Rate: Minimizes customer friction
- >51% True Positive Rate: Maximizes detection accuracy
- 99% Accuracy: Almost perfect, indicating excellent identification of non-fraud
- 82-94% Precision: Most flagged cases are indeed fraud
- 0.76 AUC-ROC Score: Good model discrimination
- Production Ready: Scalable architecture for real-world deployment
Report
(Please refer to the Jupyter Notebook available in the repository linked at the bottom of this page.)
EDA
- Application Volume
- ~2,700 daily applications with high volatility
- ~19,000 weekly applications (more stable)
- Fraud Indicators
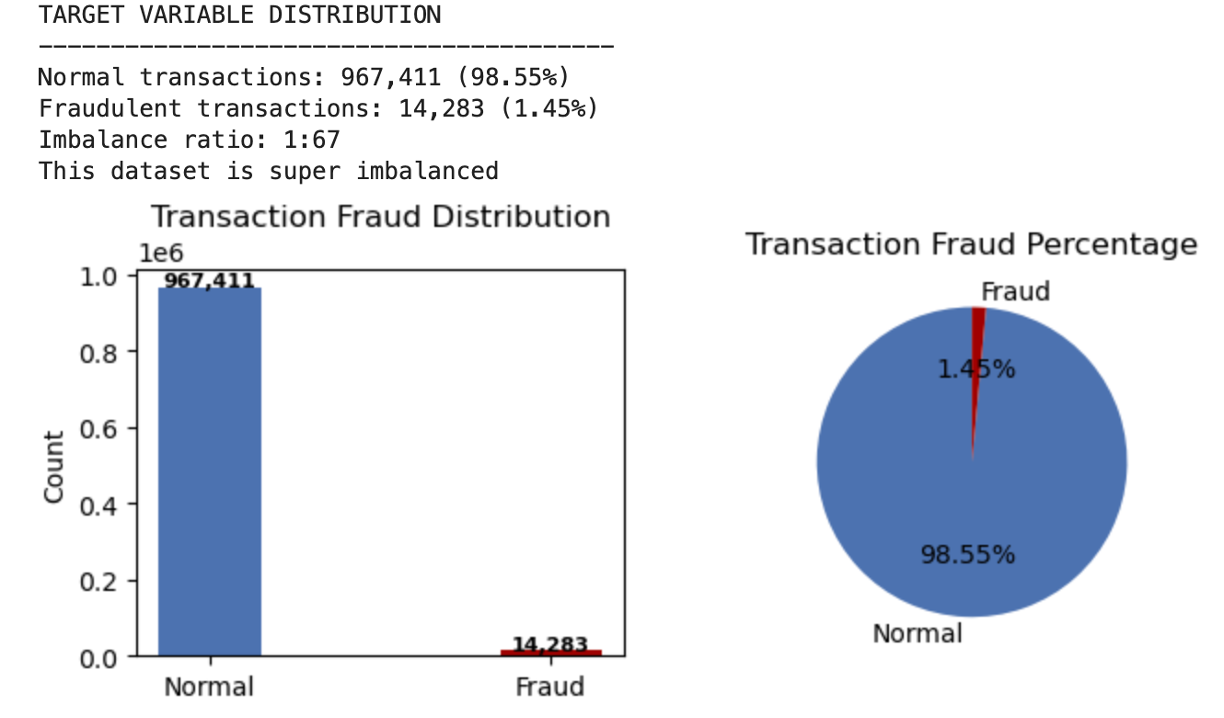
- 1.45% overall fraud rate (14,283 of 981,694 transactions)
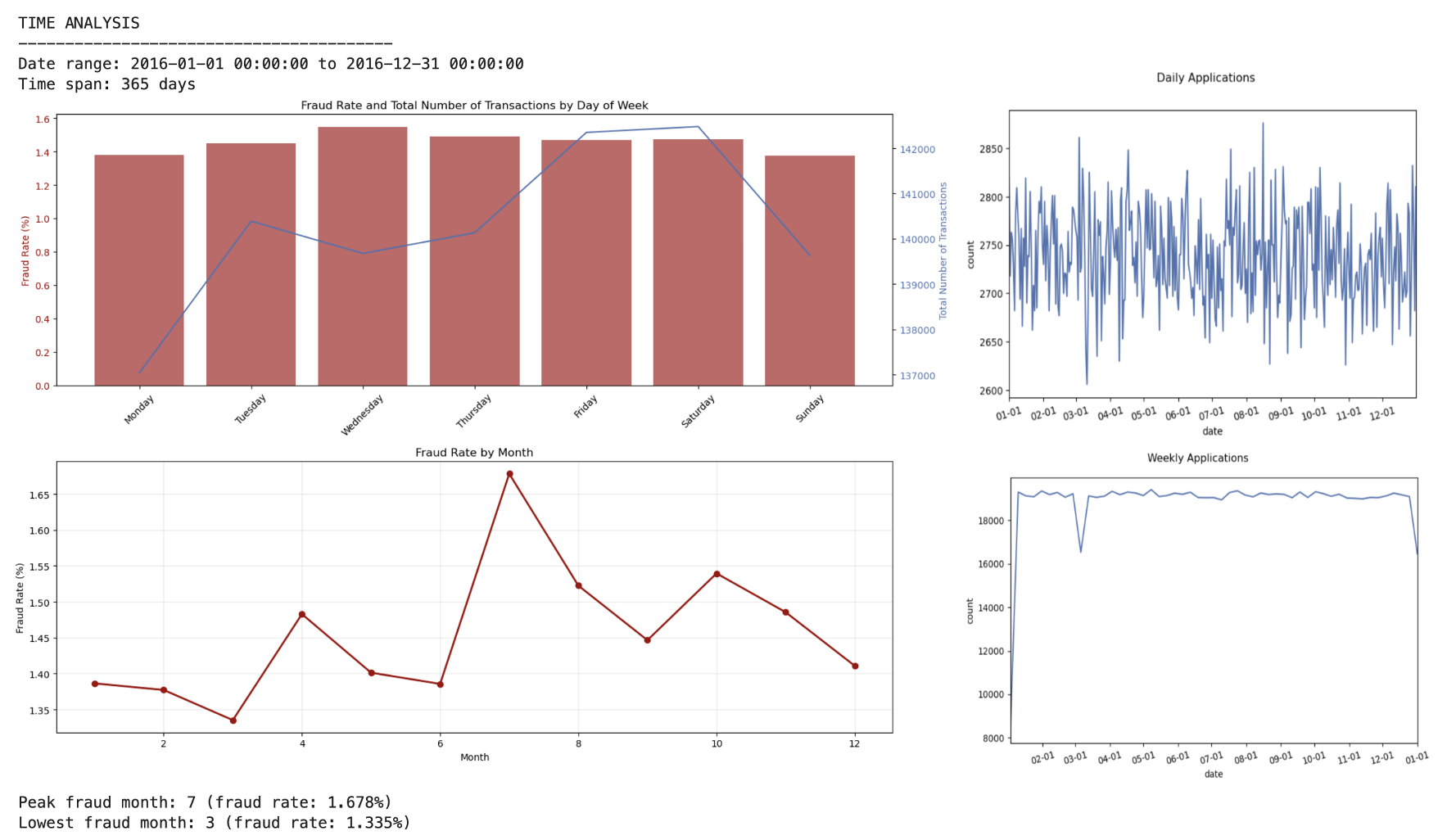
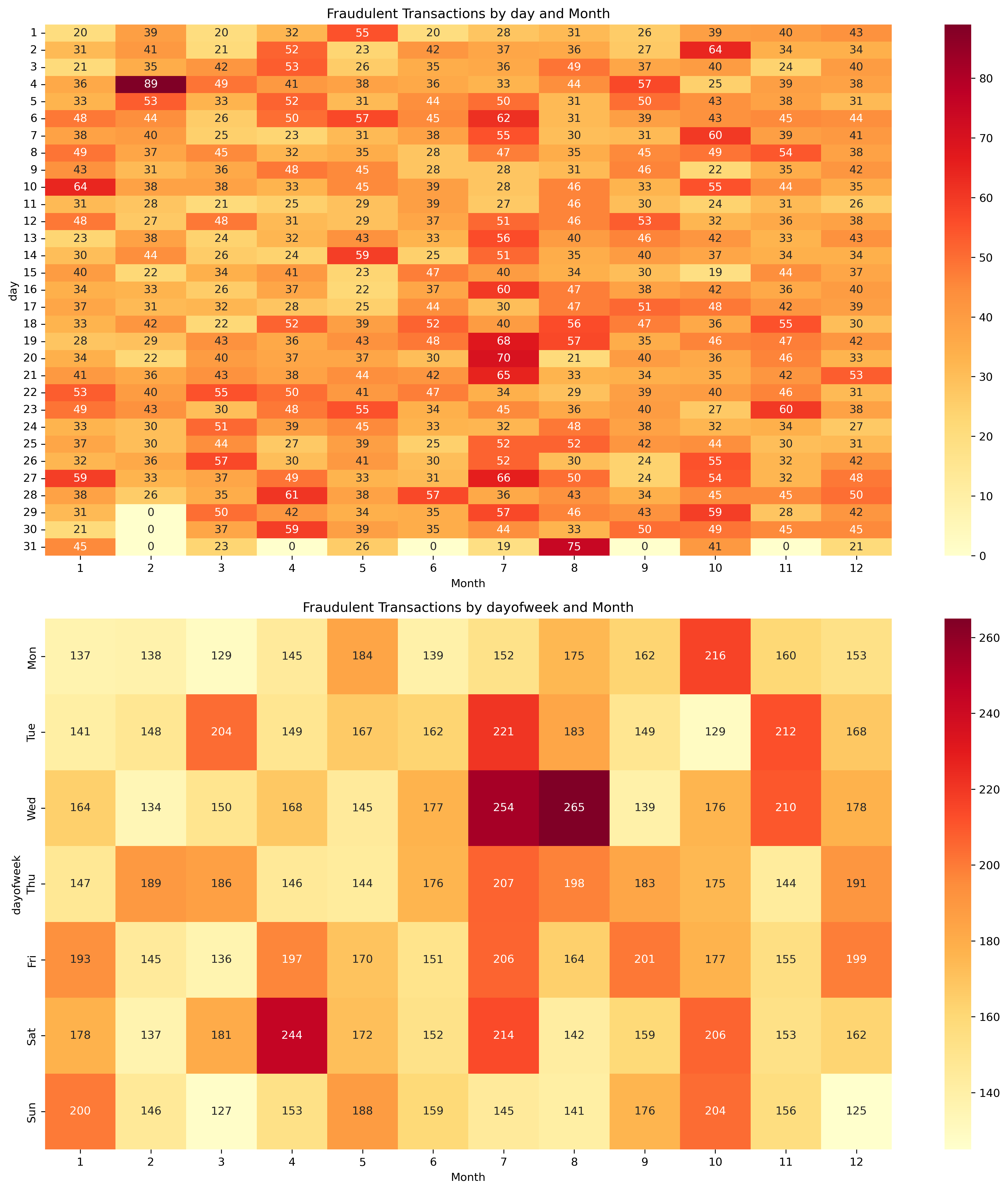
(1)Temporal Patterns
- Day 2 of each month shows high fraud
- Mid-month periods (days 14-20) elevated risk
- Summer months (Jun-Aug) have highest fraud activity
- Notable drops in late March and December
- Peak fraud in July (1.68%), lowest in March (1.33%)
- Wednesdays in July-August particularly vulnerable
- No weekend effect on fraud rates
(2)Geographic Patterns
- High fraud ZIP codes identified
- ZIP code 41310 has highest fraud rate
- Geographic clustering may be useful for modeling
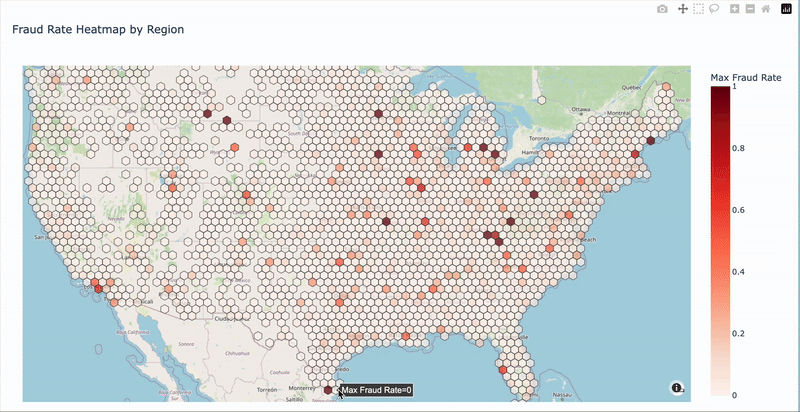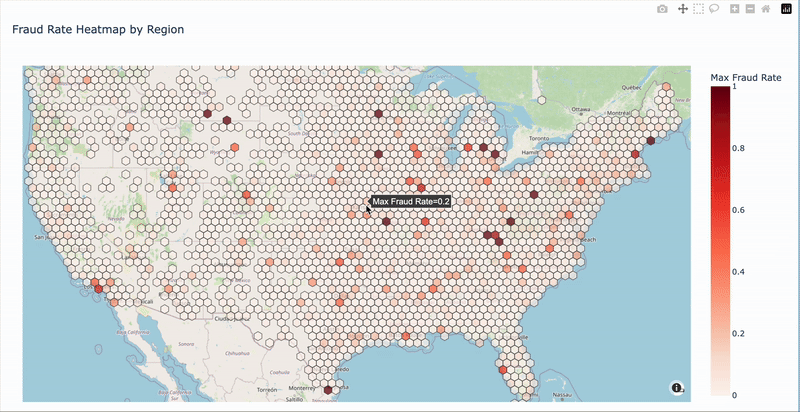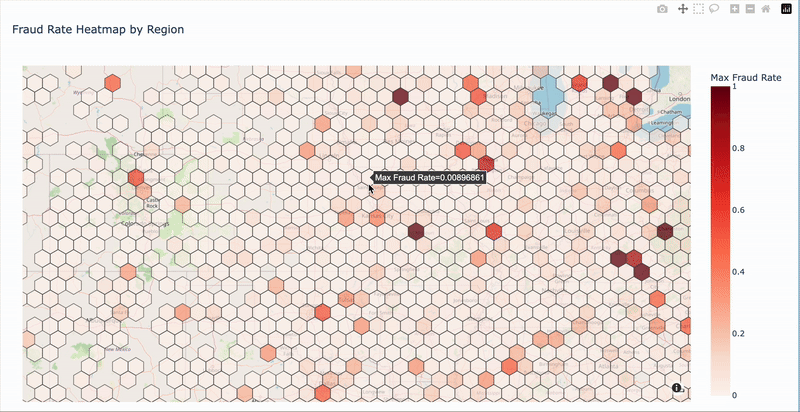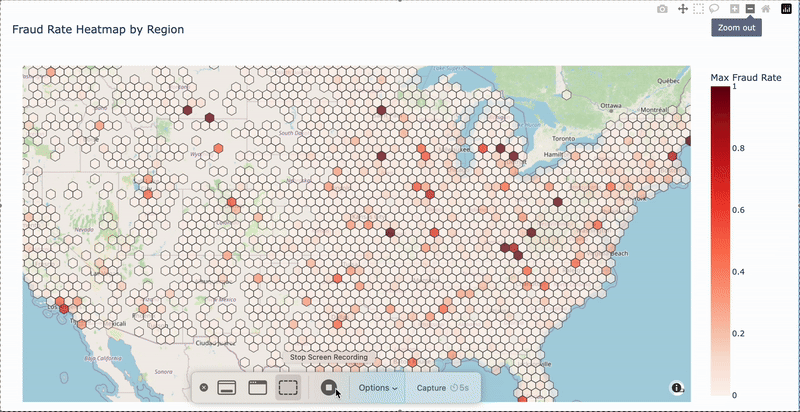 Access the interactive map: Fraud Rate Map
Access the interactive map: Fraud Rate Map - Red Flags
- One SSN used 10,000+ times
- Phone “999999999” used ~10,000 times
- Las Vegas addresses heavily concentrated
- Clear synthetic identity fraud patterns
- 💰Recommendations
- Implement real-time duplicate SSN detection
- Block obvious fake phone numbers
- Enhanced monitoring on day 2 of each month
- Increase scrutiny during summer months
Feature Engineering
Expand the dataset from 9 features to 485 features, then reduced to 38 with filter and wrapper.
- Entity-Centric Features
- Generated features by cross-linking key identity attributes (e.g.,
ssn,dob,address,phone,name) - Calculated frequency-based features across multiple rolling time windows (0, 1, 3, 7, 14, 30 days)
- Introduced
*_day_sincefeatures to capture recency of related activity
- Generated features by cross-linking key identity attributes (e.g.,
- Temporal Risk Signals
- Extracted day-of-week (
dow) and mapped it to smoothed fraud rates (dow_risk) - Captured cyclical fraud behavior patterns while mitigating data sparsity
- Extracted day-of-week (
- Composite Identity Construction
- Created compound identifiers (e.g.,
name_dob,name_fulladdress,ssn_name_homephone) - Enhanced fraud signal strength by modeling identity reuse and synthetic combinations
- Created compound identifiers (e.g.,
- Efficient Large-Scale Processing
- Applied chunked processing and DuckDB SQL pipelines for fast, scalable computation
- Reduced memory usage and execution time when engineering features for ~1 million records
- Feature Selection and Ranking
- Used KS statistics and Fraud Detection Rate (FDR) to rank 485+ features
- Selected top 70 based on average ranking, then applied RFECV to retain 38 optimal features
- Features were selected for both predictive power and interpretability
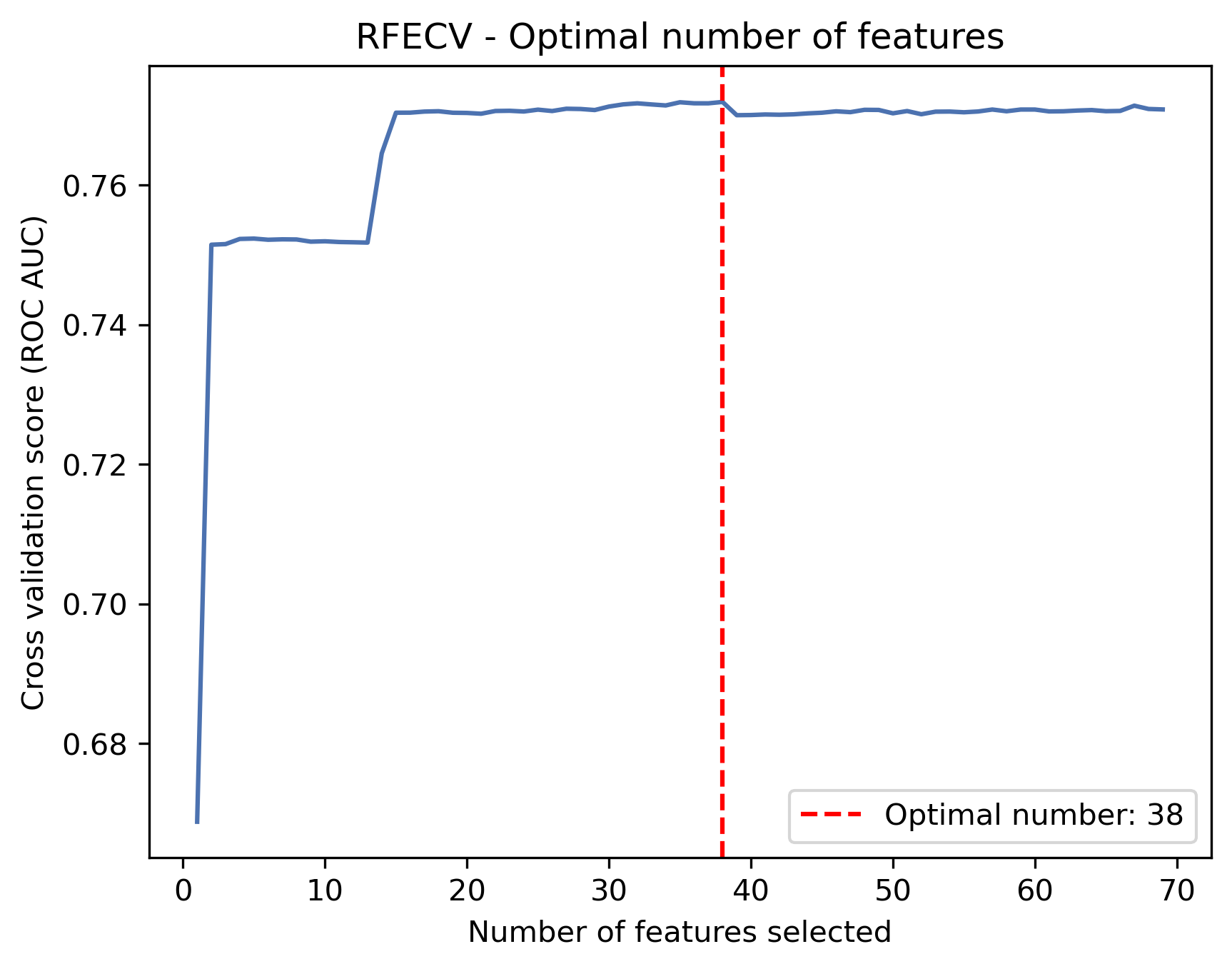
- Dimensionality Reduction & Model Readiness
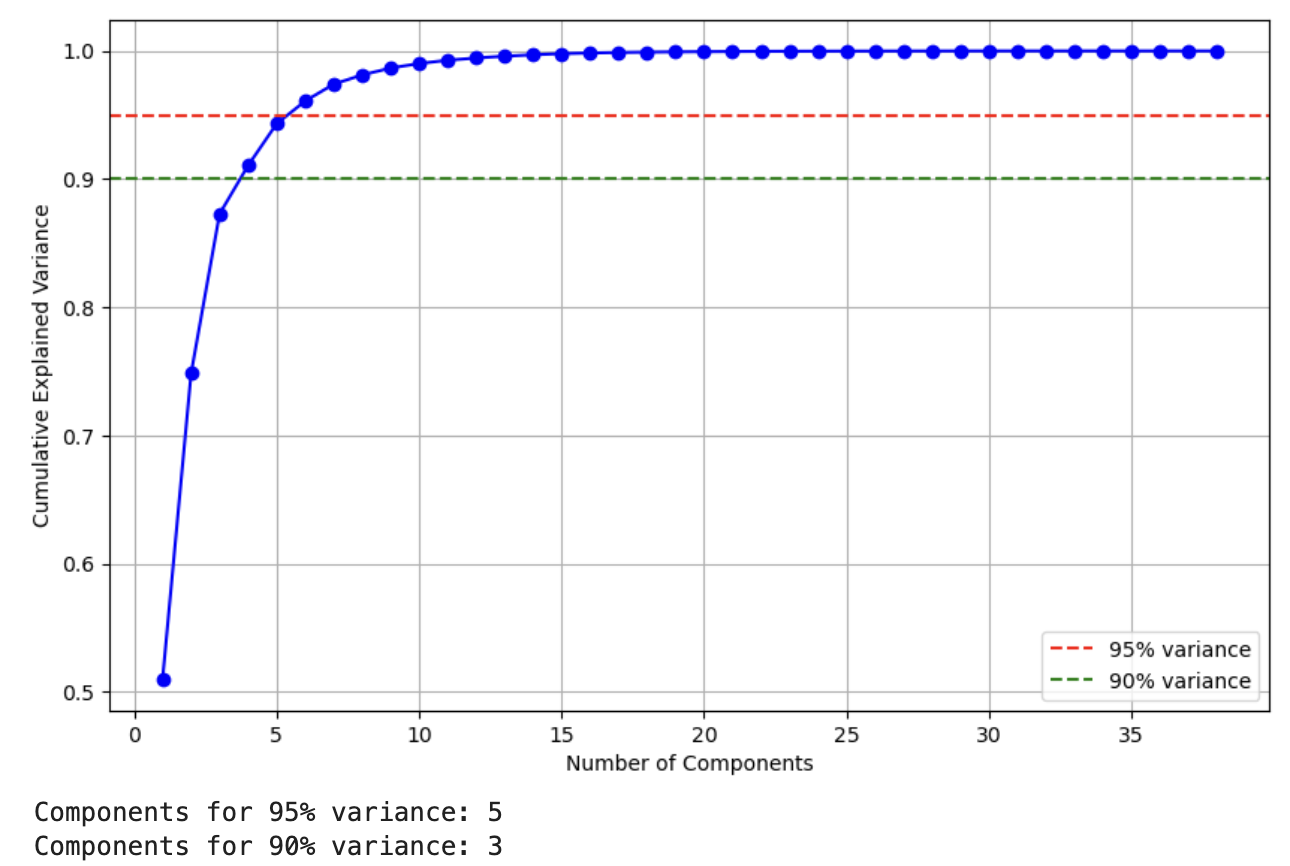
- PCA showed that 5 components explained >95% of variance, with stable AUC across 3–10 components
- Random Forest + PCA cross-validation yielded AUC ≈ 0.766, confirming robustness of engineered features
- Standardization
- Finally z-scaled the dataset and store it.
Modeling
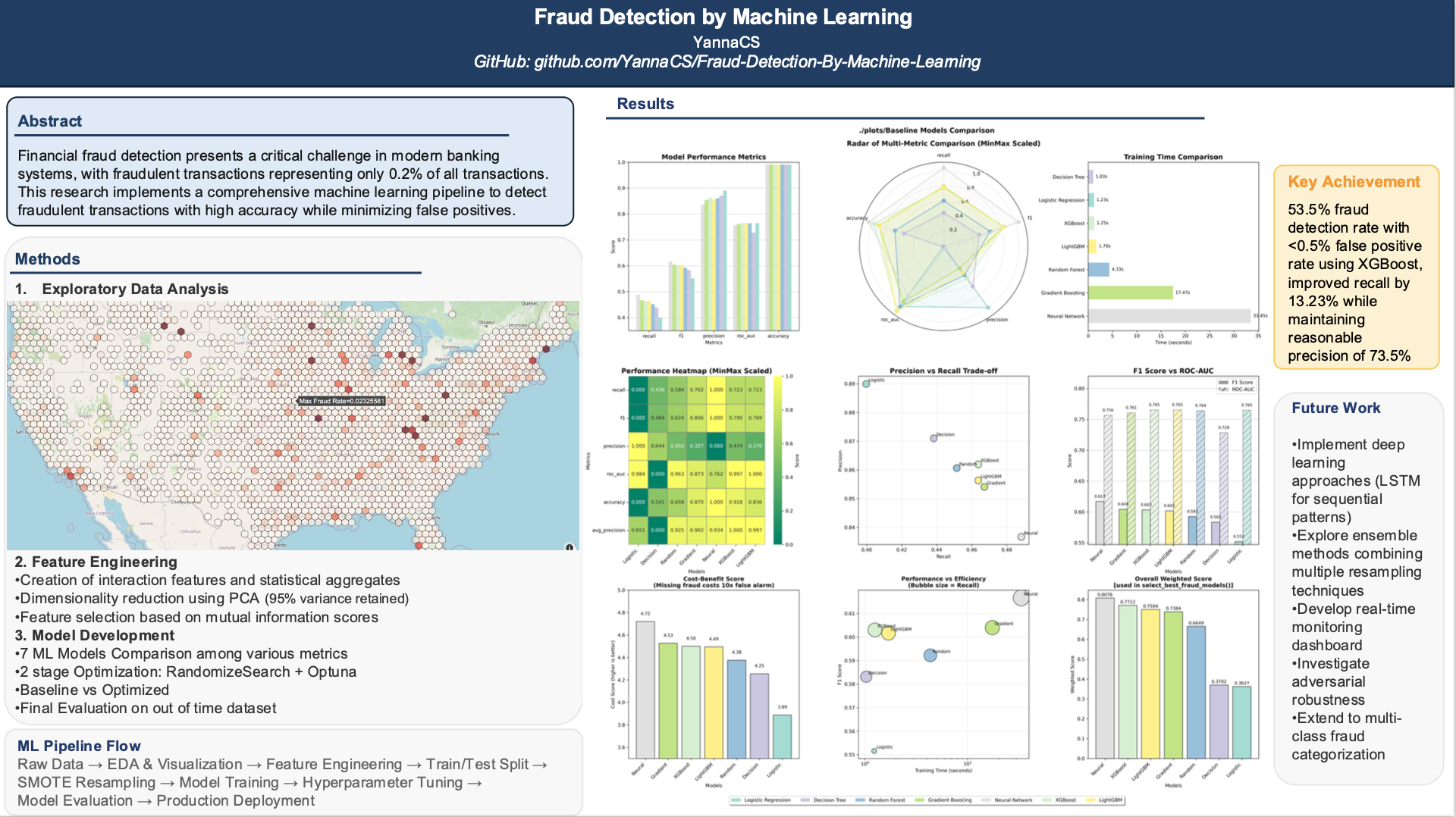
- Baseline Model Performance
- Seven models tested: Logistic Regression, Decision Tree, Random Forest, Gradient Boosting, Neural Network, XGBoost, and LightGBM
- XGBoost and LightGBM showed best ROC-AUC scores (~0.765), indicating superior discrimination ability
- Neural Network achieved highest F1 score (0.617) among baseline models
- Training times varied significantly: Logistic Regression fastest (~1.2s), Neural Network slowest (~33s)
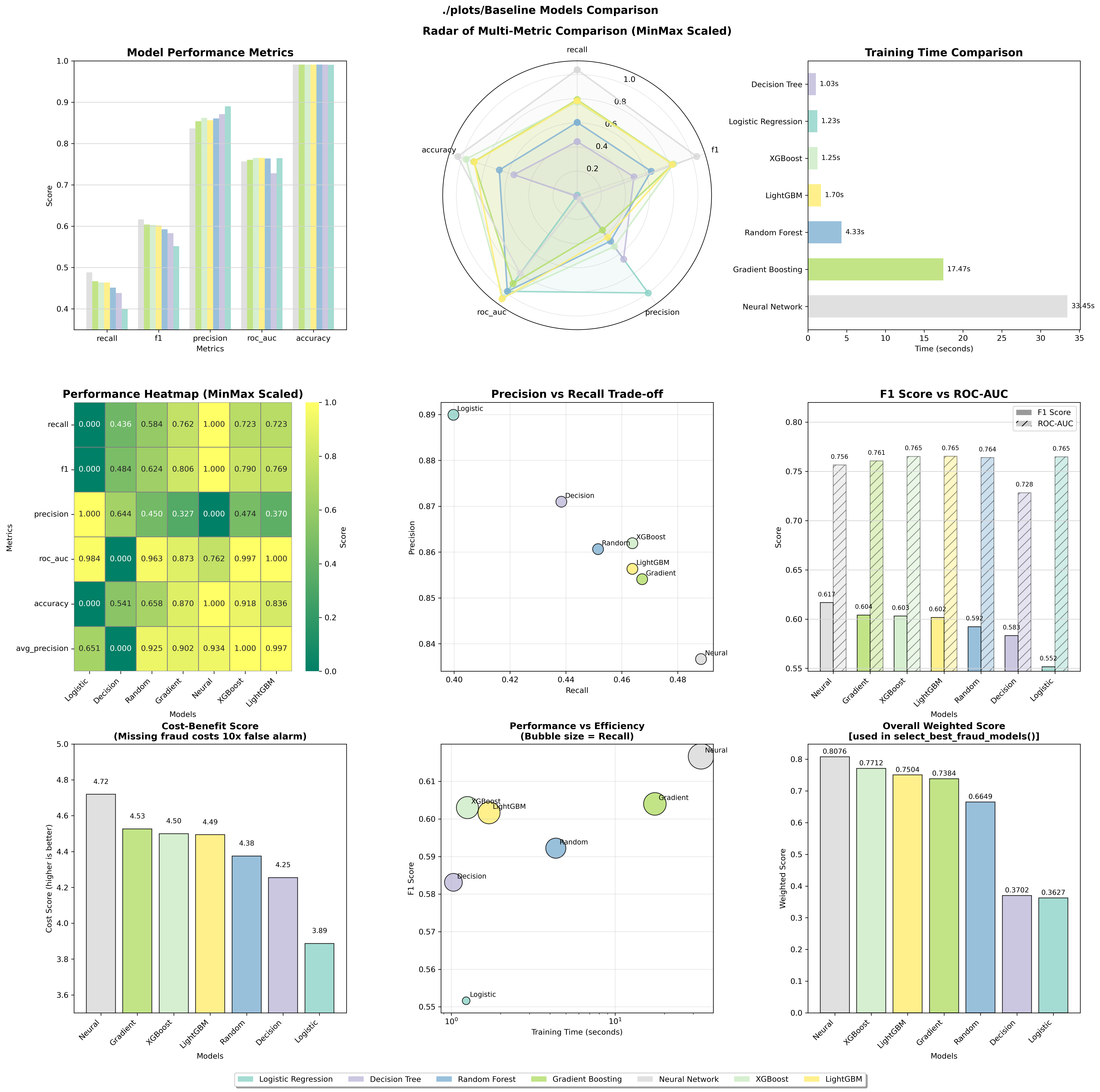
- Model Selection Strategy
- Custom weighted scoring implemented to prioritize fraud detection metrics:
- Recall: 35% (most important - catch fraud cases)
- F1: 25% (balance of precision and recall)
- Precision: 15% (avoid false alarms)
- ROC-AUC: 15% (overall discrimination)
- Average Precision: 10% (performance across thresholds)
- Top 3 models selected automatically based on the weighted score: Neural Network, XGBoost, and LightGBM (Gradient Boosting added manually)
- Custom weighted scoring implemented to prioritize fraud detection metrics:
- Hyperparameter Optimization
- Two-stage optimization approach used:
- Stage 1: RandomizedSearch for exploration
- Stage 2: Optuna for focused exploitation (can switch to hyperparameter)
- Optimization results mixed:
- All models showed decreased F1 scores after optimization
- XGBoost and LightGBM improved recall by ~13% but lost ~12% precision
- Gradient Boosting showed smallest performance drop
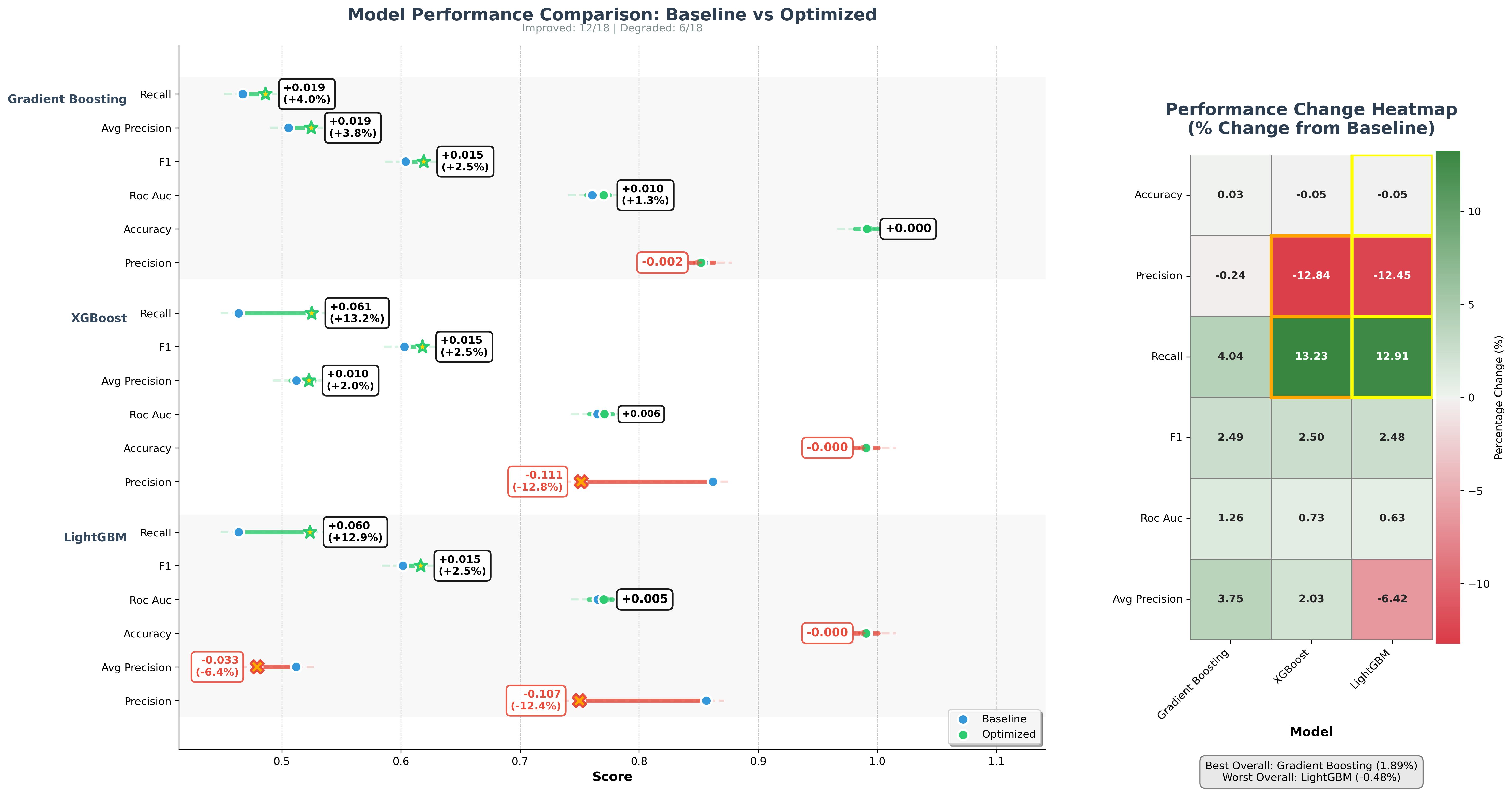
- Two-stage optimization approach used:
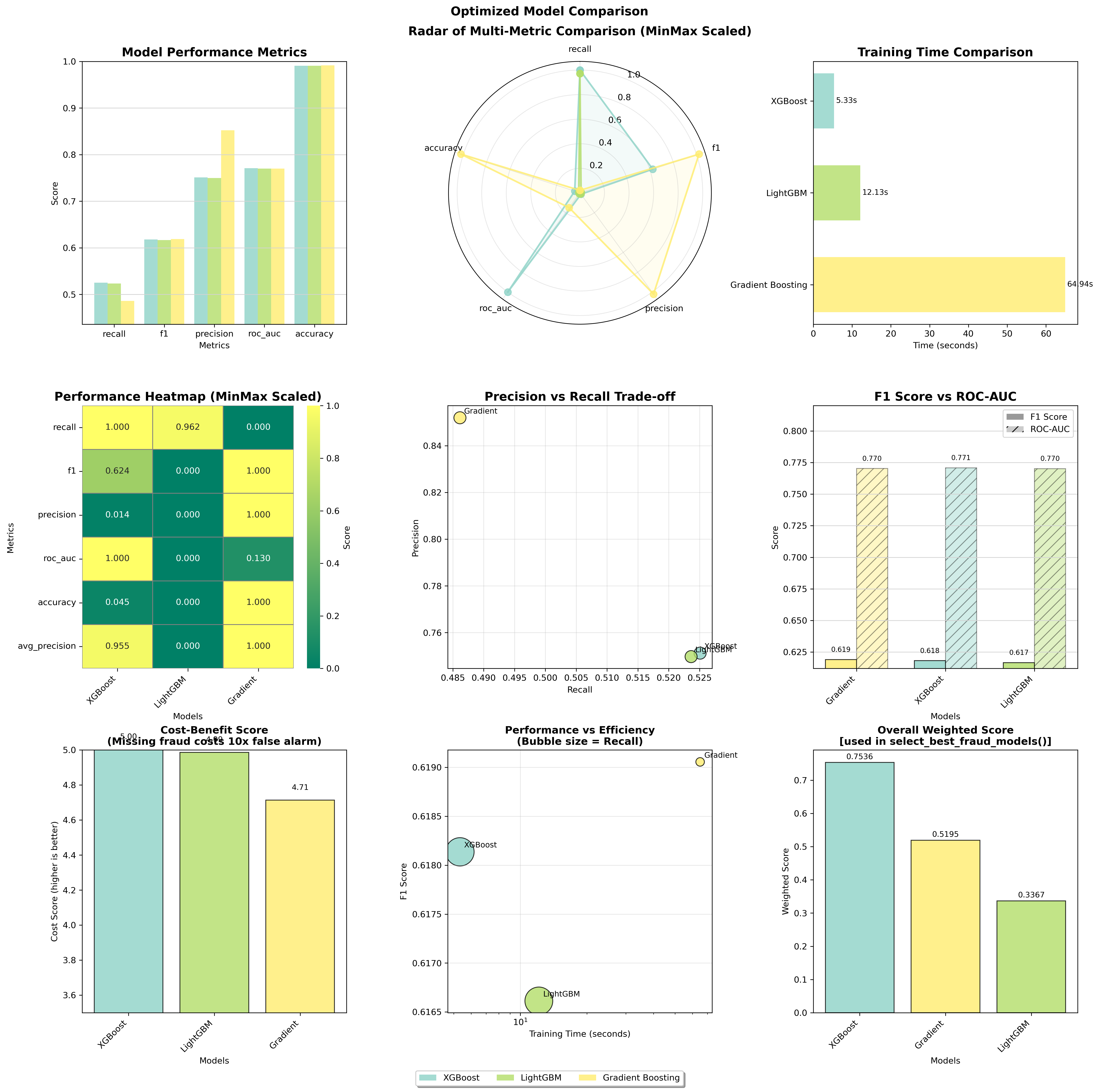
- Final Model Comparison
- XGBoost selected as best model based on weighted scoring
- Key performance metrics (XGBoost):
- ROC-AUC: 0.771
- F1 Score: 0.618
- Recall: 0.526 (52.6% of fraud cases caught)
- Precision: 0.751 (75.1% of flagged cases are actual fraud)
- False Positive Rate: 0.0026-0.0028
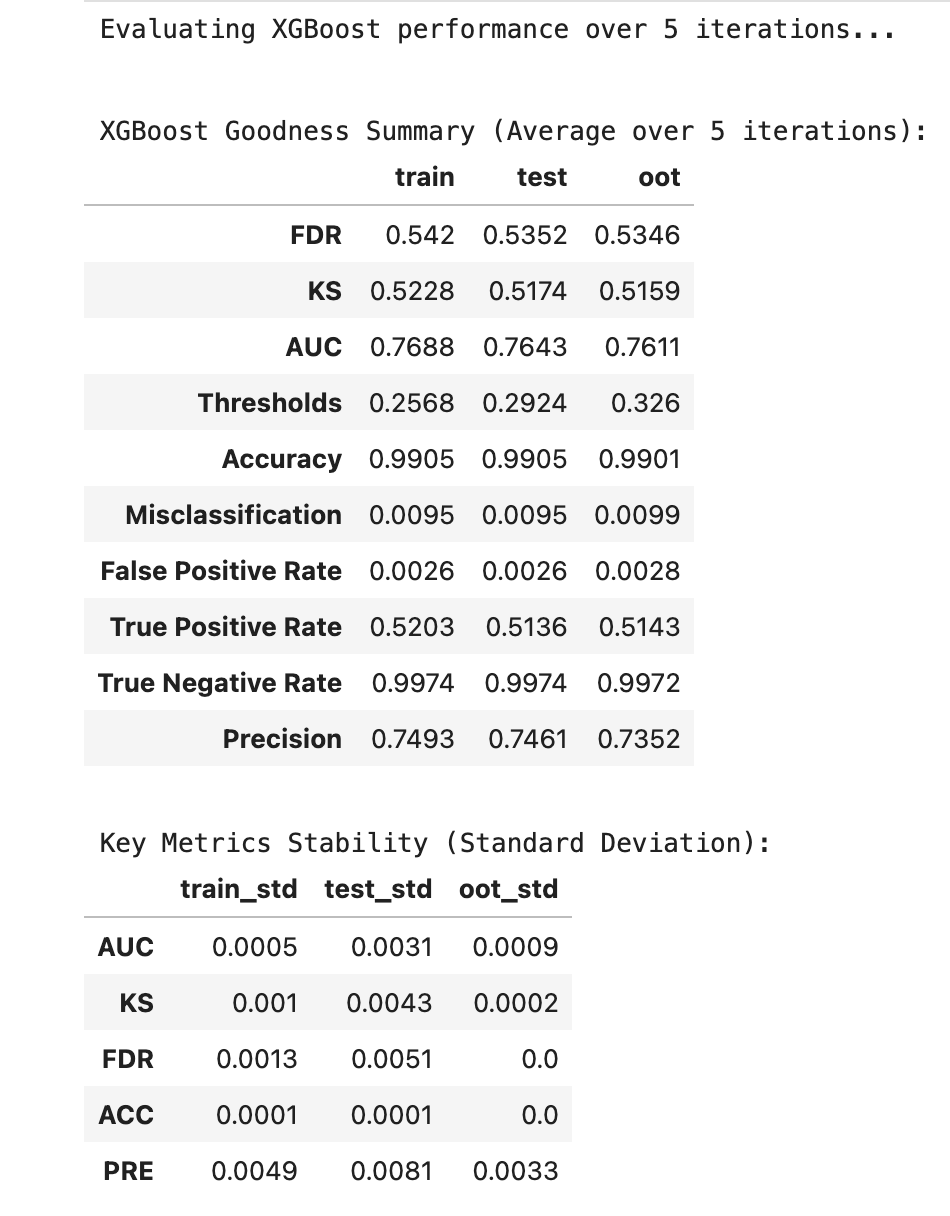
- Model Stability Analysis
- XGBoost showed excellent stability across train/test/out-of-time datasets
- Minimal performance degradation from training to test sets
- Consistent fraud capture rates (~84% in top bin, ~16% fraud rate in highest risk segment)
- 💰Business Implications
- Trade-off identified: XGBoost has higher false positive rate (2.6-2.8 per 1000) compared to historical GBDT model (0.5-1.4 per 1000)
- Recommendation: Consider XGBoost for production if false positives are critical concern
- Top 5% of scored transactions capture 84% of fraud cases, enabling efficient review strategies
Technology Stack
- Python
- Scikit-learn
- XGBoost
- TensorFlow/Keras
- Pandas & NumPy
- Matplotlib & Seaborn
- SMOTE (imbalanced-learn)
- Jupyter Notebooks